No Such Blog or Diary
メモリが余っているのでRamdiskにする
- 2012-01-10 (Tue)
- 一般
Dataram RAMDisk を入れて4GBほどをディスク化.システムのテンポラリと Chrome のキャッシュを置くことにした.
以下,RAMDisk,Crucial M4 SSD,HITACHIの4TBのHDD,HITACHIの古い2TBのHDDのベンチマーク結果.まあ,HDDはだいぶ使い込んでいる状況のものなのでアレだけど,RAMDiskはやっぱりケタが違う.
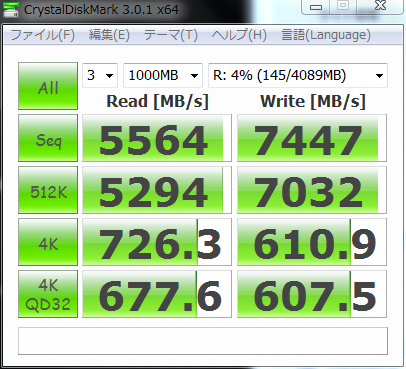
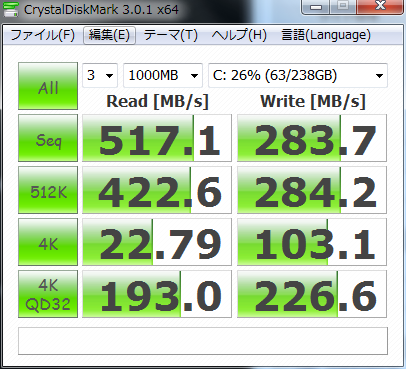
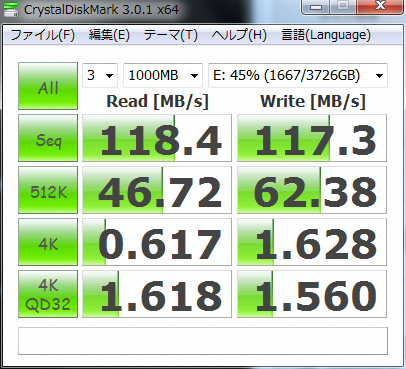
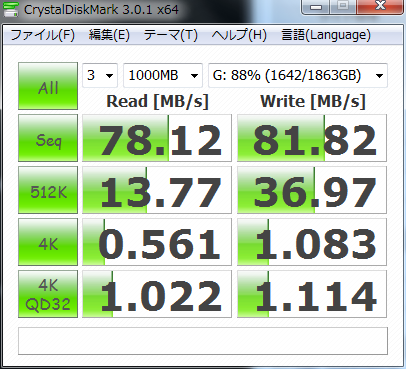
SSDと4TBはX79の6GbpsのSATAで2TBは別チップの6GbpsのSATAで繋いでたっけ.まあ,HDDに関してはインターフェースの帯域は関係なさそうだけど.とりあえず SSD はSATA3.0でももう危ないんじゃなかろうか?
閑話休題.
休止モードでコケるのでスリープを使うことにした.これまではマザーボードのせいなのかスリープできなかったので休止モードを使っていたのだけど,新しい構成のPCではスリープが成功するので休止モードを使う必要がなくなったし.
- Comments: 0
- TrackBack (Close): -
あー、HDCP対応とかでないとダメか
- 2012-01-09 (Mon)
- 一般
EISOのS170が余っているので BUFFALO の地デジ専用HDDレコーダ DVR-1Cを付けて遊ぼうかと思ったら画像が映らねぇ.HDMI→DVI-Dのケーブルでつないで解像度的には720pで問題ないはずなのだけど.メインディスプレイのLCD2690WUXiでは問題なく映るし.
んで,よく考えるとS170ってHDCP非対応なのよね.なのでデジタル接続では映像を映せない気がする.
アナログで出してアップスキャンコンバータ使えばいいけれど…… とりあえずちょっと残念な気分.
- Comments: 0
- TrackBack (Close): -
とりあえず安定した
- 2012-01-08 (Sun)
- 一般
メモリテストも終了したので Windows 7 を入れなおして環境をもろもろ再構築.ついでにデータのバックアップをして一日終了.
つか,去年の冬までのRAWデータを全て消してしまっていたことに今日気づいた…… できの良い部分だけは残しとけばよかったなぁ.まあ,いいか.
閑話休題.
今のところ速くなったなぁと実感する部分なし.
- Comments: 0
- TrackBack (Close): -
新しい暖房を組み立てた
- 2012-01-07 (Sat)
- 一般
メインマシンの P6T Deluxe V2 の BIOS をアップデートしたら windows が起動しなくなったので,再インストールするならついでに一式パワーアップしてしまえと以下の構成に変えてみた.なんとなく LGA 1155 を選んだら負けかなと思ったので LGA 2011 で.
CPU:Intel i7-3930K CPUクーラー:Intel RTS2011AC M/B:Asus P9X79 DELUXE メモリ:UMAX DDR3-16000 4G×4枚セットx2
i7-920 からの置き換えなので,4コア→6コア,トリプルチャネル6GB→クワッドチャネル32GB,USB3.0たくさん,SATA3.0たくさん,といった感じにパワーアップ.メモリこんなにいらない気もするけれど,安かったので多くしてみた.かわりにグラボは250GTSのままでしょぼい.
とりあえず片面だけ痛いイラストの入った紙袋であったことにあとで気づいた……
- Comments: 0
- TrackBack (Close): -
携帯新調
- 2012-01-06 (Fri)
- 一般
MEDIASの動作が不安定になってきたしそもそも物理的に壊れ始めてきたのでARROWSに換えた.ついでにFOMAからXiに切り替わったのでテザリングしてもパケット定額の上限が変わらなくなってちょっと嬉しい.そして自宅だと3Gの電波は弱いけどLTEの電波は強いらしい.
とりあえず環境を整えて最低限使える状況に復帰.マーケットでソフトを検索しているときにC/C++コンパイラとかいうのがあったけれどあれは使えるのだろうか? 暇な時に試してみようか.
- Comments: 0
- TrackBack (Close): -