No Such Blog or Diary
cachegrind... 遅い…
- 2009-12-25 (Fri)
- プログラミング
valgrind --tool=cachegrind でキャシュミスを調べようと思ってプログラムを走らせたのだが… 計算が終了する気配が無い.データサイズ小さくすりゃ速くなるだろうけど,そしたらデータがキャッシュ乗り切ってしまうので本末転倒.
まあ,キャッシュ効きまくり状態でも50秒かかるのだからシミュレーションでキャッシュの計測とかしてたらなかなか終わらんか.うーん,この実験を繰り返すのは苦痛だなぁ.
- Comments: 0
- TrackBack (Close): -
.info ドメイン10円とか
- 2009-12-24 (Thu)
- 一般
お名前.com のクリスマスセールで .info ドメインが1年10円とか(最大10年までの一括契約で10円 + 二年目以降920円/年).メールとURLの転送サービスも只になるっぽい.
とりあえず幾つか捨てドメインとして取得 → 1年後に気に入ったものだけさくらに移管,かな.でも「キャンペーン期間中に登録したドメインは以後の更新料金も920円/年となります。」ってのが本当ならさくら(1800円)より安いなぁ.不安なのは試しに更新のページに行ってみたら3000円オーバーの金額が書かれていたことだけど….とりあえず一年後に考えよう.
- Comments: 0
- TrackBack (Close): -
find コマンドで特定の時刻より新しいファイルを探す
- 2009-12-24 (Thu)
- ソフトウェア ( Linux/coLinux )
エクスプローラでの検索方がわからないので find に逃げた.オプションの -newer を使えば,指定したファイルより新しいファイルを列挙してくれる.そしてファイルの時間を変えるには touch コマンド使えば良いと.
ということで,find と touch のコンボで特定時刻より新しいファイルを探す(2009/12/24 19:15より新しいの):
touch -t 200912241915 timebase; find . -newer timebase
ひょっとしたら touch なんかいらずに find だけで出来るかもしれないけど man find が動かず find --help しか見れない今の状況では上の方法で必要十分.
そして firefox のディスクアクセスをRamDiskに押し付けたいが *.sqlite とかどうしようかと悩むところ.
- Comments: 0
- TrackBack (Close): -
はぢめてのRAID
- 2009-12-24 (Thu)
- ハードウェア
HDDひとつの容量が2TBとかに増えたのは良いけれど,容量増加は不慮の事故によるデータ喪失の被害量も多くしてしまう.臆病者としてはこの状況には耐えられえない.
ということで,2TB x4 で RAID5 を組んだ: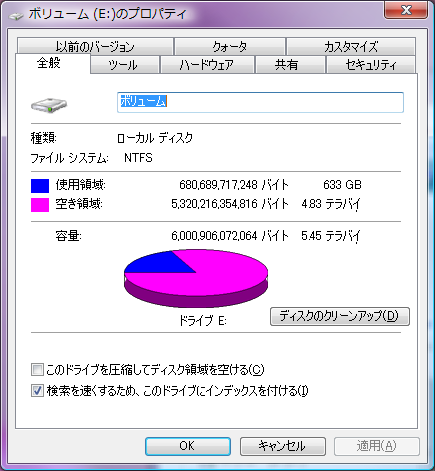
使った箱は裸族のインテリジェントビルで,HDDにはHITACHIの13k円のやつを使った.2TB x4 の RAID5 なので,使える容量は 6TB になっている.
どう考えても臆病者の使う機材ではない気もするけれど…
そしてCrystalDiskMark2.2.0での計測結果を.以下,HDD単体,4台でのRAID5,RAMDISKの順番: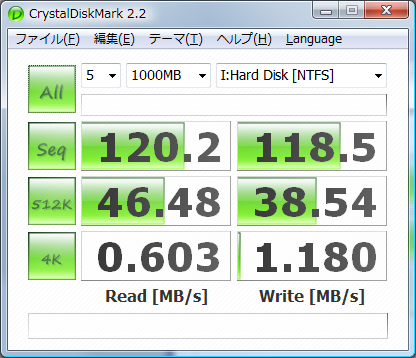
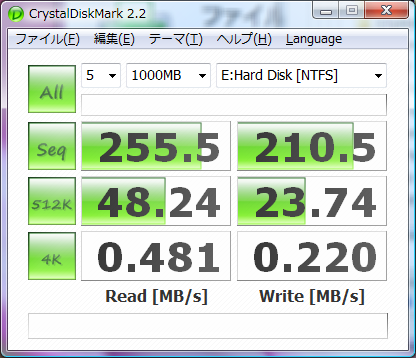
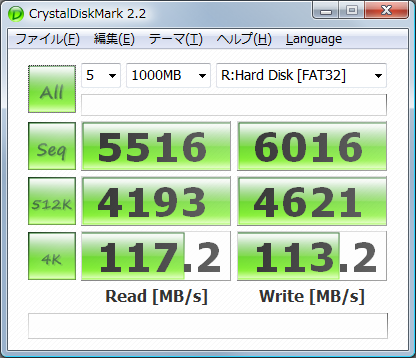
RAIDのシーケンシャルの読み書き速ェー(2倍出てるね).でもそれ以外遅ェ―(512kランダムリードで同じくらい.他は性能ダウン).まあ,RAID5なので書き込みが遅いのは仕方がない.そしてやっぱRAMはケタが違う.
ついでにもう一つ.テストサイズを小さくしてやった結果.HDD/RAID/RAMの順: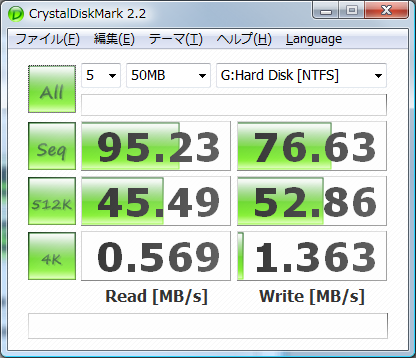

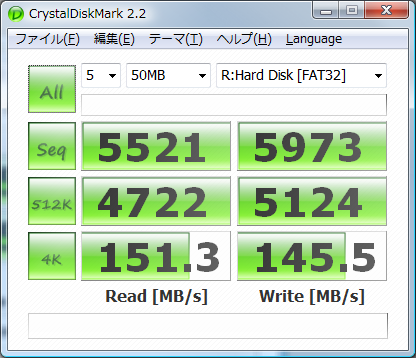
まあ,基本何も変わらない.1000MBの結果と違ってRAIDのランダムリードが速いのは,多分HDDのキャッシュの総計が大きくなってるからだろう.それにしてもRAMDISKが速すぎる…
- Comments: 0
- TrackBack (Close): -
黒酢酢豚弁当
- 2009-12-23 (Wed)
- 一般
久々に大学の前のほっともっとで弁当を買った.今月の新メニューの黒酢酢豚弁当.
うん,酢豚自体は美味しい.
が,見た目のチープさにより美味しさ半減なのが残念な気がする….弁当の容器が共通だからボリューム足りないように見えたり,ご飯がどこかの容器で固めたのを嵌め込みましたという形をしていたり.
見た目を良くするぐらいなら味と価格の改善をしてほしいと思うのが普通だが,できればメニュー表とかPOPの写真からのギャップは少なくしていただきたい.
そしてオリジンの酢豚弁当(黒酢風味)とどっちが美味しいかはオリジンの方を食べてないので分からない.でも値段はオリジンの圧勝だったはず → 490円 vs. 390円で100円安いらしい.言い換えるとほっともっとの方が25%高い値段.その差が味に現れるか量に現れるか値段だけなのかは分からない.
- Comments: 0
- TrackBack (Close): -
久々にSRMに出てみたら
- 2009-12-23 (Wed)
- 一般
250点問題のシステムテストでコケた.途中でキーボードが言うこと効かなくなった.二分探索が再帰関数の中に入った.そして1500に下がった.
- Comments: 0
- TrackBack (Close): -